JavaScript 工作原理 —— V8引擎透视 + 5个编写优化代码的技巧
潘忠显 / 2021-04-02
“JavaScript 工作原理”系列文章是翻译和整理自 SessionStack 网站的 How JavaScript works。因为博文发表于2017年,部分技术或信息可能已经过时。本文英文原文链接,作者 Alexander Zlatkov,翻译 潘忠显。
笔者认为,通过了解 JavaScript 的基本组成以及它们工作原理,开发者可以编写出更好的代码和应用。
《JavaScript 工作原理 —— 引擎、运行时和调用栈概述》重点介绍了引擎、运行时和调用堆栈的概述。本文作为第二篇文章,将深入探讨Google V8 引擎内部的组成部分。
概述
JavaScript 引擎是执行 JavaScript 代码的程序或解释器。 JavaScript 引擎可以实现为标准解释器,也可以实现为实时编译器 (JIT compiler),将 JavaScript 编译为某种形式的字节码。
以下是热门的 JavaScript 引擎项目列表:
- V8 — 开源,由Google开发,用C ++编写
- Rhino — 由Mozilla基金会管理,开源,完全使用Java开发
- SpiderMonkey — 第一个JavaScript引擎,该引擎过去支持Netscape Navigator,如今已支持Firefox
- JavaScriptCore — 开源,由Nitro运营,由Apple为Safari开发
- KJS — KDE的引擎,最初是由Harri Porten为KDE项目的Konqueror网络浏览器开发的
- Chakra (JScript9) — Internet Explorer
- Chakra (JavaScript) — Microsoft Edge
- Nashorn — 作为OpenJDK的一部分开放源代码,由Oracle Java Languages and Tool Group编写
- JerryScript — 是用于物联网的轻量级引擎
为什么研发V8引擎
Google 的开源项目 V8 引擎是以 C++ 编写的,该引擎在Google Chrome内部使用。同时,V8 还被用作时下流行的 Node.js 的运行时。

V8 最初旨在提高 Web 浏览器中 JavaScript 执行的性能。为了提高运行速度,V8 将 JavaScript 代码转换为更高效的机器代码,而不是使用解释器。它通过实现一个即时编译器 (JIT compiler),可以在执行时,将JavaScript代码编译为机器码,其他许多现代JavaScript引擎也是这么做的,如SpiderMonkey或Rhino(Mozilla)等。他们的主要区别是:V8不会产生字节码或任何中间码。
V8 曾经的两个编译器
在v5.9版本之前,V8 使用两个编译器:
- full-codegen:一个简单快速的编译器,用于生成简单但相对较慢的机器代码
- Crankshaft:一个复杂的 (JIT) 优化的编译器,用于生成高度优化的代码
V8引擎内部会使用几个线程:
- 主线程完成用户期望的工作:获取代码,编译,执行
- 单独的编译线程:在主线程执行的同时,进行代码优化
- 单独的profiler线程:提供给Crankshaft判断哪些方法更耗时以进行优化
- 垃圾收集器(Garbage Collector)进行垃圾清理的额外一些线程
首次执行 JavaScript 代码时,V8使用 full-codegen,它直接将已解析的 JavaScript 转换为机器代码,而无需任何中间转换,这使它可以“非常快地”开始执行机器代码。V8 没有使用中间字节码表示,因而消除了对解释器的需求。
代码运行了一段时间后,profiler 线程收集到了足够的数据,可以判断对哪些方法应该进行优化。
接下来,另一个线程开始 Crankshaft 优化。它将 JavaScript 抽象语法树转换为叫做 Hydrogen 的高级静态单分配(SSA, static single-assignment)表示形式,并尝试优化该 Hydrogen graph。大多数优化都是在这一等级上完成的。
内联 (Inlining)
第一个优化是预先内联尽可能多的代码。内联是将调用站点(调用函数的代码行)替换为被调用函数体的过程。(译注:类似于C语言中的include展开)。这个简单步骤,使得后续优化更有意义。
隐藏类 (Hidden class)
JavaScript 是一种基于原型的 (prototype-based) 语言:没有类,创建对象依靠克隆过程(a cloning process)。JavaScript 还是一种动态编程语言,这意味着,可以在对象实例化之后,轻松地添加或删除属性。
大多数 JavaScript 解释器都使用类似于字典的结构(基于哈希函数),将对象属性值的位置存储在内存中。相对于非动态编程语言(比如Java),JavaScript的这种存储结构,导致它在检索属性的值需花费更多的计算资源。原因在于:在Java中,所有对象属性均由编译前的固定对象布局确定,并且无法在运行时动态添加或删除;因为属性固定,可以将属性的值(或指向这些属性的指针)作为连续缓冲区存储在内存中,并且在每个缓冲区之间具有固定的偏移量,可以轻松确定不同属性偏移量。而在 JavaScript 中,在运行时属性类型可以更改的情况下,就无法通过偏移的方式来快速访问某一属性。
由于使用字典来查找对象属性在内存中的位置非常低效,因此 V8 使用了一种技巧:隐藏类。隐藏类的工作方式类似于 Java 之类的语言中使用的固定对象布局(类),不同之处在于隐藏类是在运行时创建的。现在,让我们以以下代码为例进行解释(创建一个Point对象 p1):
function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
一旦调用 new Point(1, 2),V8 会创建一个称为 C0 的隐藏类。
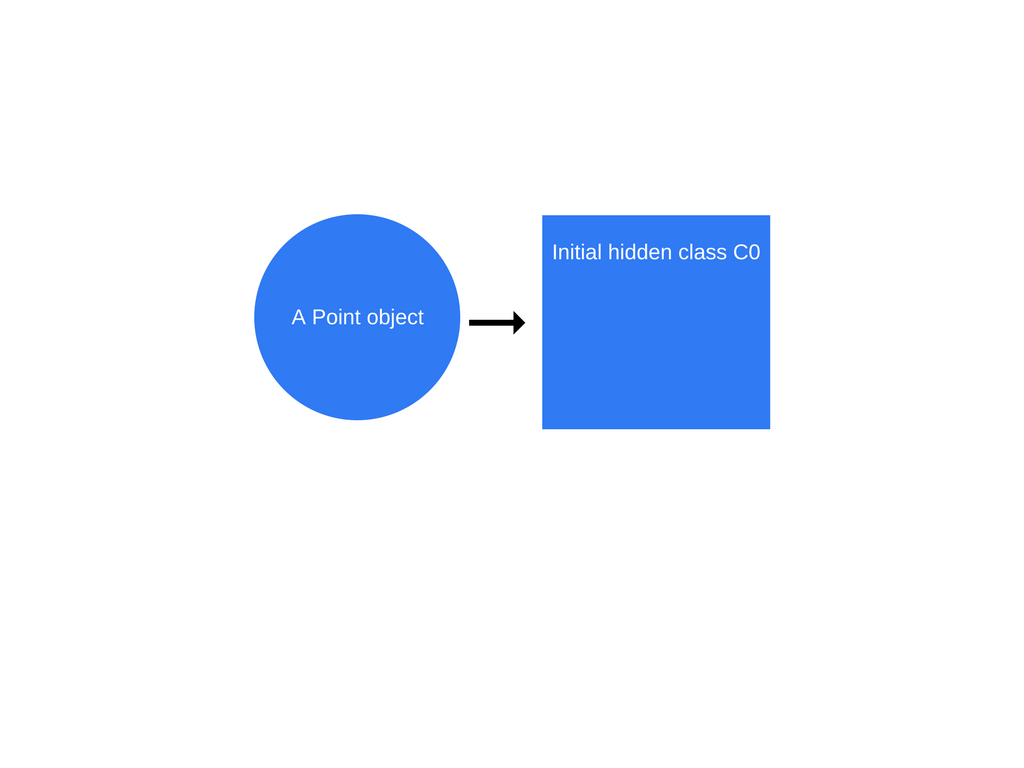
因为尚未为 Point 定义任何属性,所以 C0 是空的。
一旦执行了第一条语句 this.x = x,V8 将创建一个基于 C0 的第二个隐藏类 C1。C1 描述了x 位于内存中的、相对于对象指针的偏移位置,即在什么地址可以找到属性 x 。在这种情况下,x 存储在 offset 0 处。这意味着:若要在内存中查看作为连续缓冲区的Point对象时,首个偏移将对应于属性 x(译注:指针指向x)。V8 还将用类转换更新 C0,让其表达:如果一个属性 x 被添加到Point对象,隐藏类应当从 C0 切换到 C1。现在,表示Point对象的隐藏类是现在的C1。
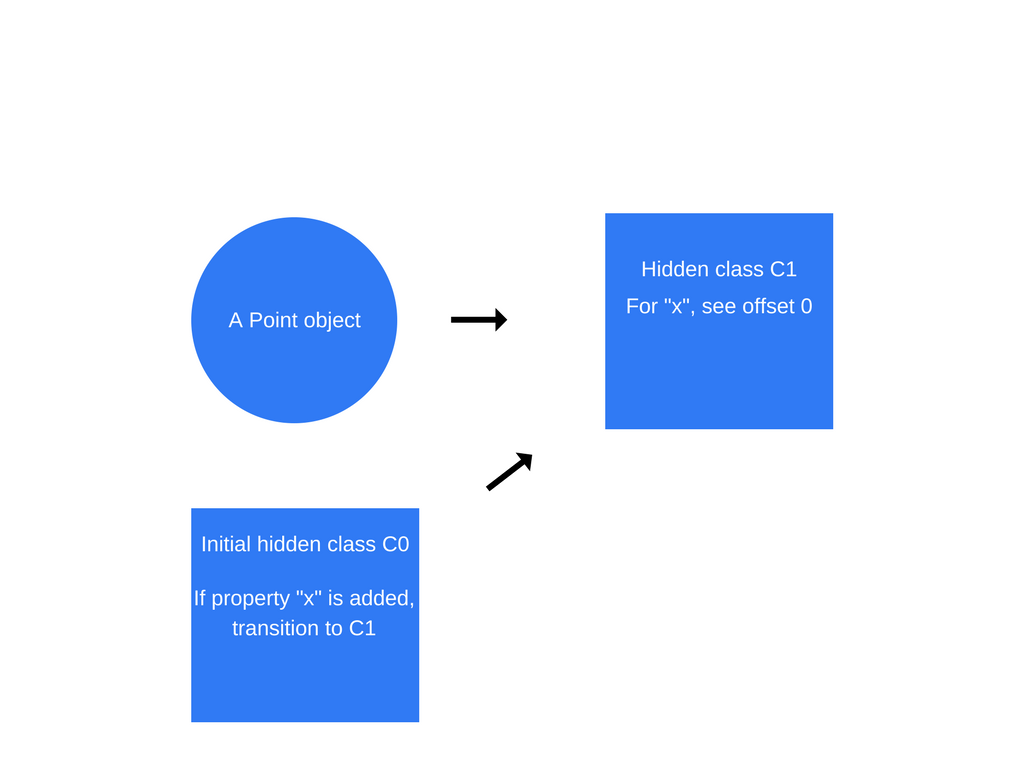
每次给对象添加新属性时,都会使用到新隐藏类的过渡路径 (transition path) 来更新旧的隐藏类。在以相同方式创建的对象之间,可以通过隐藏类来共享,因此隐藏类转换非常重要。如果两个对象共享一个隐藏类,并且它们两个都添加了相同的属性,则过渡将确保两个对象都接收到相同的新隐藏类,以及随之而来的所有优化代码。
当执行语句 this.y = y 将会重复上边 this.x = x 这一类转换的过程。创建了一个名为 C2 的新隐藏类,将一个类转换添加到 C1,表明如果将属性 y 添加到Point对象(C1已经包含属性 x),则隐藏类应变更成为 C2,并且Point对象的隐藏类更新为 C2。
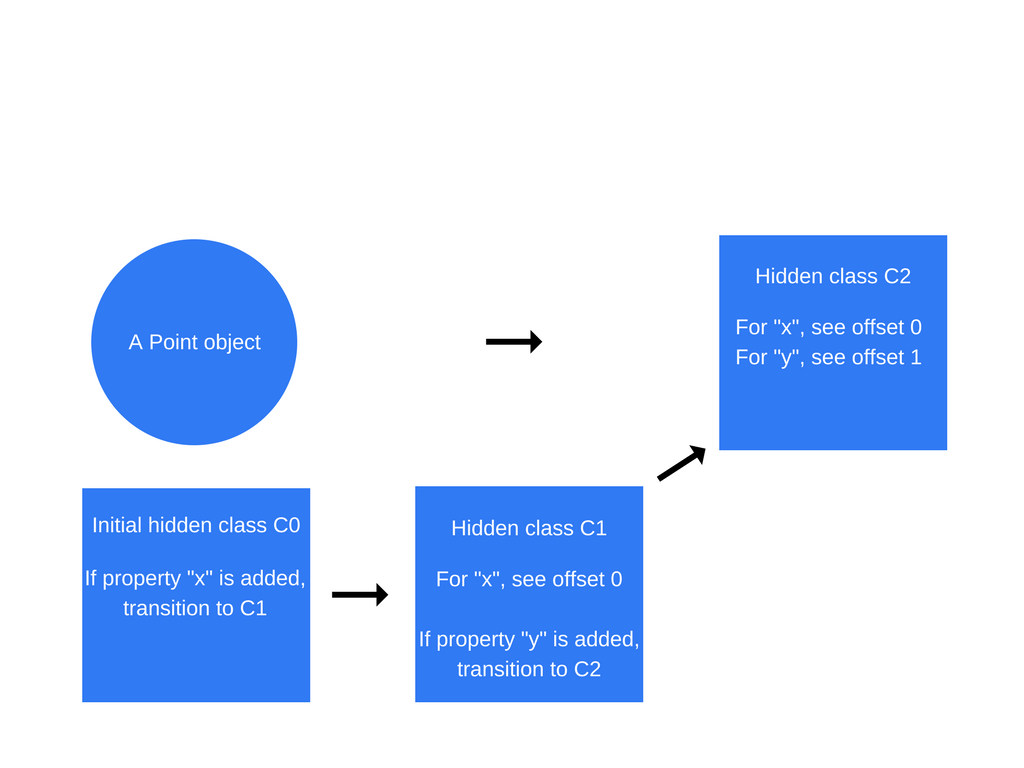
隐藏类过渡需要依赖添加到对象的属性顺序。请看下边的代码:
function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
p1.a = 5;
p1.b = 6;
var p2 = new Point(3, 4);
p2.b = 7;
p2.a = 8;
你可能觉着 p1 和 p2 使用相同的隐藏类和过渡。其实不然!对于 p1 而言,首先添加属性 a,然后再是属性 b。而对 于p1 而言,首先添加属性 b,然后再是属性 a。因此两个对象是使用不同的过渡产生的不同隐藏类。这类例子中,最好保持相同的动态属性初始化顺序,以便能复用隐藏类。
内联缓存 (inline caching)
V8 利用了另一种用于优化动态类型语言的技术,称为内联缓存。内联缓存依赖于对作用在相同类型对象的、重复调用相同方法的趋势观察。更深入的讨论内联缓存说明,可以点击这里查看。如果您没时间详细阅读深入说明,我们这里也将介绍一些内联缓存的一般概念
V8 维护着一个对象类型缓存,缓存的是最近被作为参数传递到调用方法中对象,并假设这些对象类型将来也会被作为参数传递。如果V8能较准确的预测被传递到方法中的对象类型,那么他就可以绕过寻找如何访问对象属性的过程,使用以前查找到对象的存储信息作为替代。
隐藏类和内联缓存两个概念有什么联系?每当在特定对象上调用方法时,V8 引擎都必须对该对象的隐藏类执行查找,以确定用于访问特定属性的偏移量。在对相同隐藏类的相同方法成功调用两次之后,V8 会忽略隐藏类的查找,仅简单地将属性的偏移量添加到对象指针上。对于之后该方法的所有调用,V8 引擎假定隐藏类未更改,并使用先前查找中存储的偏移量直接跳到特定属性的内存地址。这大大提高了执行速度。
内联缓存也是同类型对象共享隐藏类之所以如此重要的原因。如果创建两个具有相同类型但具有不同隐藏类的对象(前边示例中的 p1 和 p2),V8 将无法使用内联缓存,因为这两个对象虽属于同一类型,但它们各自的隐藏类为它们的属性分配不同的偏移量。

编译机器码
当 Hydrogen graph 被优化时,Crankshaft 会将其转成为更低级别的表达形式(称之为Lithium)。大多数 Lithium 实现都是特定于计算机架构,寄存器分配也在此级别进行。
Lithium 最终会被编译为机器码。接下来是被称为 OSR 的堆栈替换。在我们开始编译和优化明显会长时间运行的方法之前,我们可能已经在运行它了。V8 不是先记录执行缓慢的方法,然后再次启动的时候使用优化版本。相反,他会将所有上下文(栈、寄存器)进行转换,以便于我们能够在执行过程中切换到优化后的代码。再加上其他优化,V8 初始化时的内联代码是一项很复杂的任务。不过,V8 引擎也不是唯一能做到这点引擎。
有一些称为反优化 (deoptimization) 的保护措施,在假设引擎不使用的场景下,可以反向转换成未优化的代码。
垃圾收集 (Garbage collection)
关于垃圾收集,V8 使用传统的方法,通过标记清除 (mark-and-sweep) 的方式来清理垃圾 (old generation)。
标记阶段 (marking phase) 需要停止 JavaScript 执行。为了控制垃圾回收成本并使执行更加稳定,V8使用了增量标记:不是遍历整个堆(尝试对每个可能的对象进行标记),而是只遍历堆的一部分,然后恢复正常执行。下一次垃圾收集,会从上一次堆遍历停止的位置继续进行。这种方式允许在正常执行期间非常短的暂停。如前所述,清除阶段 (sweep phase) 由单独的线程处理。
Ignition and TurboFan
2017年初5.9版本的V8发布,引入了新的执行管道 (execution pipeline)。该管道实现了更大的性能改进,并在现实 JavaScript 应用显著的节省了内存。新的执行管道基于 V8 的解释器 Ignition 和 V8 最新的优化编译器 TurboFan。
自5.9版本问世以来,V8 团队一直在努力追求 JavaScript 语言新特性,因此 full-codegen 和Crankshaft(自2010年起为V8服务的技术)不再被 V8 用于 JavaScript 执行,这些功能需要针对新特性进行优化。这意味着整个V8将来将具有更简单、更可维护的体系结构。
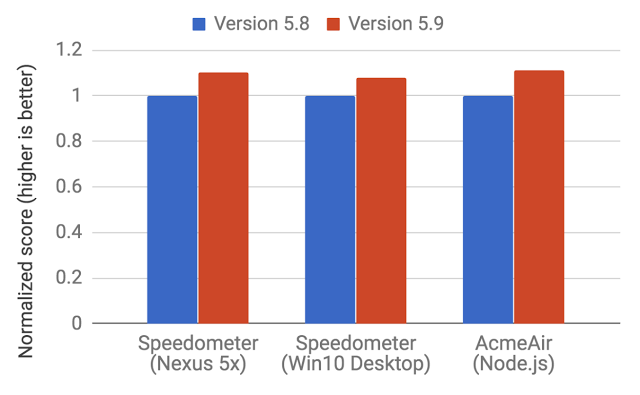
这些改进仅仅是开始,新的 Ignition 和 TurboFan 管道为进一步优化铺平了道路,这些优化将在未来几年内提高 JavaScript 性能并缩小 V8 在 Chrome 和 Node.js 中的占用空间。
最后,您可以从上面的内容中轻松得出如何编写良好优化的、更好的 JavaScript 的提示和技巧。但是,为方便起见,做简单的摘要如下:
编写优化 JavaScript 的5个技巧
- 对象属性的顺序:始终以相同的顺序实例化对象属性,以便可以共享隐藏的类以及随后优化的代码。
- 动态属性:实例化后向对象添加属性将强制更改隐藏类,已经为上一个隐藏类优化过的方法都会因此而变慢。替代措施是在构造函数中分配对象的所有属性。
- 方法:由于内联缓存 (inline caching) 的原因,重复执行相同方法将比仅执行一次许多不同方法的代码运行更快。
- 数组:避免键不是递增数字的稀疏数组。里面没有所有元素的稀疏数组是一个“哈希表”。访问这样数组中的元素耗费更大。另外,避免预先分配大数组,在使用中逐渐增长更好。最后,不要删除数组中的元素,它使键更稀疏。
- 标记值 (tagged values):V8 使用 32 位表示对象和数字。它使用 32 bit 中的一个 bit 来标记变量是对象(
flag = 1),还是的整数(flag = 0),这个整数被称为”小整数(SMI, SMall Integer)“,因为它只有31 bit。如果数值大于31位,则V8会将数字装箱 (box),将其变成double并创建一个新对象以将数字放入其中。尽可能使用 31 bit 带符号的数字,以避免对 JS 对象进行昂贵的装箱操作。