潘忠显 / 2021-04-20
“JavaScript 工作原理”系列文章是翻译和整理自 SessionStack 网站的 How JavaScript works。因为博文发表于2017年,部分技术或信息可能已经过时。本文英文原文链接,作者 Alexander Zlatkov,翻译 潘忠显。
How JavaScript works: exceptions + best practices for synchronous and asynchronous code

Jan 5 · 9 min read
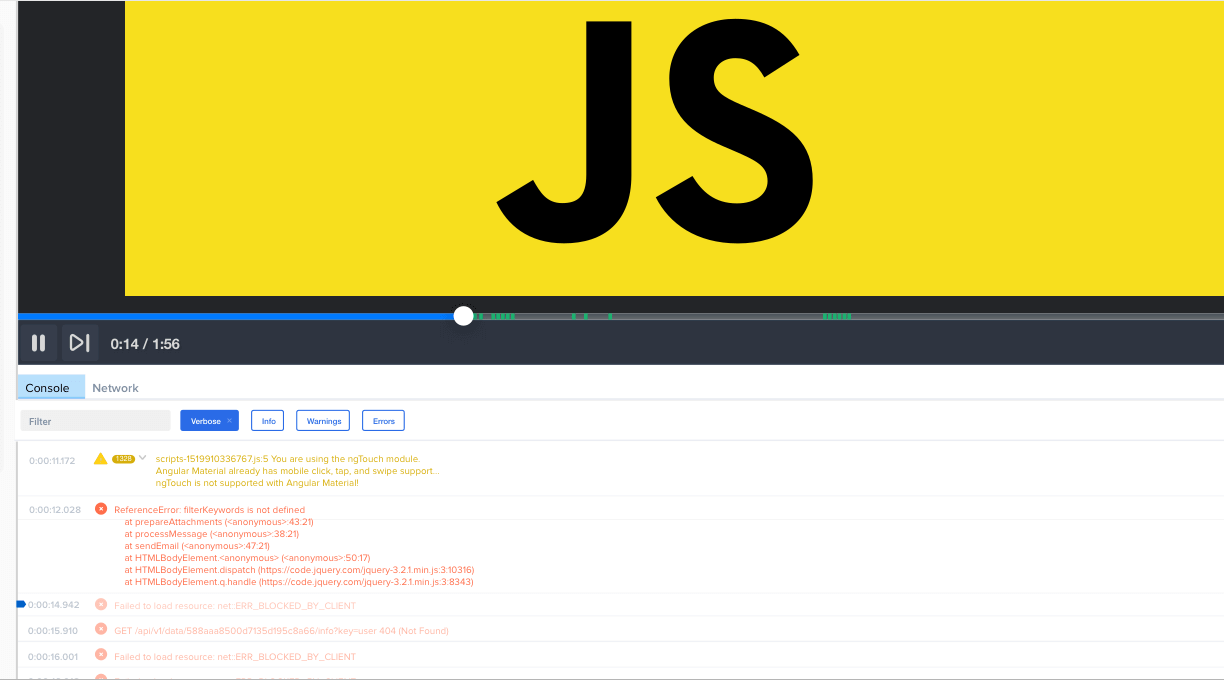
Errors in the browser console
This is post # 20 of the series, dedicated to exploring JavaScript and its building components. In the process of identifying and describing the core elements, we also share some rules of thumb we use when building SessionStack, a JavaScript application that needs to be robust and highly-performant to help companies optimize the digital experience of their users.
If you missed the previous chapters, you can find them here:
- An overview of the engine, the runtime, and the call stack
- Inside Google’s V8 engine + 5 tips on how to write optimized code
- Memory management + how to handle 4 common memory leaks
- The event loop and the rise of Async programming + 5 ways to better coding with async/await
- Deep dive into WebSockets and HTTP/2 with SSE + how to pick the right path
- A comparison with WebAssembly + why in certain cases it’s better to use it over JavaScript
- The building blocks of Web Workers + 5 cases when you should use them
- Service Workers, their life-cycle, and use cases
- The mechanics of Web Push Notifications
- Tracking changes in the DOM using MutationObserver
- The rendering engine and tips to optimize its performance
- Inside the Networking Layer + How to Optimize Its Performance and Security
- Under the hood of CSS and JS animations + how to optimize their performance
- Parsing, Abstract Syntax Trees (ASTs) + 5 tips on how to minimize parse time
- The internals of classes and inheritance + transpiling in Babel and TypeScript
- Storage engines + how to choose the proper storage API
- The internals of Shadow DOM + how to build self-contained components
- WebRTC and the mechanics of peer to peer connectivity
- Under the hood of custom elements + Best practices on building reusable components
Overview
In computing, error detection is a technique that enables a reliable flow during the execution of the program.
One approach to error detection is error checking. This method maintains normal program flow with subsequent explicit checks for anomalies, which are reported using specific return values, an auxiliary global variable, or floating-point status flags.
An exception is the occurrence of an anomaly during the program execution, which interrupts its normal flow. Such an interruption triggers the execution of a pre-registered exception handler.
Exceptions can happen both on the software and the hardware level.
Exceptions in JavaScript
A single JavaScript application may have to run on many different operating systems, browsers + plugins, and devices. No matter how many tests you wrote, supporting such an environment of possibilities will ultimately lead to errors.
From an end-user’s standpoint, JavaScript is dealing with errors by just failing silently. Things are a bit more complicated under the hood.
A JavaScript code throws an exception when a particular statement generates an error. Instead of executing the next code statement, the JavaScript engine checks for the existence of exception handling code.
If no exception handlers have been defined, the engine returns from the function that threw the exception. This process is repeated for each function on the call stack until it finds an exception handler. If no exception handler is found and there are no more functions on the stack, the next function on the callback queue is added to the stack by the event loop.
When an exception occurs, an Error Object is created and thrown.
Types of Error Objects
There are nine types of built-in error objects in JavaScript, which are the foundation for exception handling:
- Error — represents generic exceptions. It is most often used for implementing user-defined exceptions.
- EvalError — occurs when the
eval()function is used improperly. - RangeError — used for errors that occur when a numeric variable or parameter is outside of its valid range.
- ReferenceError — occurs when a non-existent variable is accessed.
- SyntaxError — occurs when the JavaScript language rules are broken. For static-typed languages, this happens during compilation time. In JavaScript, it happens during runtime.
- TypeError — occurs when a value does not match the expected type. Calling a non-existent object method is a common cause of this type of exception.
- URIError — occurs when
encodeURI()anddecodeURI()encounter a malformed URI. - AggregateError — when multiple errors need to be reported by an operation, for example by
Promise.any(). - InternalError — occurs when an internal error in the JavaScript engine is thrown. E.g. “too much recursion”. This API is not standardized at the moment of writing this article.
You can also define custom error types by inheriting some of the built-in error types.
Throwing Exceptions
JavaScript allows developers to trigger exceptions via the throw statement.
if (denominator === 0) {
throw new RangeError("Attempted division by zero");
}
Each of the built-in error objects takes an optional “message” parameter that gives a human-readable description of the error.
It’s important to note that you can throw any type of object as an Exception, such as Numbers, Strings, Arrays, etc.
These are all valid JavaScript statements.
There are benefits to using the built-in error types instead of other objects since some browsers give special treatment to them, such as the name of the file which caused the exception, the line number, and the stack trace. Some browsers, like Firefox, are populating these properties for all types of objects.
Handling Exceptions
Now we will see how to make sure that exceptions don’t crash our apps.
The “try” Clause
JavaScript, quite similar to other programming languages, has the try, catch, finally statements, which gives us control over the flow of exceptions on our code.
Here is a sample:
try {
// a function that potentially throws an error
someFunction();
} catch (err) {
// this code handles exceptions
console.log(e.message);
} finally {
// this code will always be executed
console.log(finally’);
}
The try clause is mandatory and wraps a block of code that potentially can throw an error.
The “catch” Clause
It is followed by a catch block, which wraps JavaScript code that handles the error.
The catch clause stops the exception from propagating through the call stack and allows the application flow to continue. The error itself is passed as an argument to the catch clause.
Commonly, some code blocks can throw a different kind of exception, and your application can potentially act differently depending on the exception.
JavaScript exposes the instanceof operator that can be used to differentiate between the types of exceptions:
try {
If (typeof x !== ‘number’) {
throw new TypeError(‘x is not a number’);
} else if (x <= 0) {
throw new RangeError(‘x should be greater than 0’);
} else {
// Do something useful
}
} catch (err) {
if (err instanceof TypeError) {
// Handle TypeError exceptions
} else if (err instanceof RangeError) {
// Handle RangeError exceptions
} else {
// Handle all other types of exceptions
}
}
It’s a valid case to re-throw an exception that has been caught. For example, if you catch an exception, the type of which is not relevant to you in this context.
The “finally” Clause
The finally code block is executed after the try and catch clauses, regardless of any exceptions. The finallyclause is useful for including clean up code such as closing WebSocket connections or other resources.
Note that the finally block will be executed even if a thrown exception is not caught. In such a scenario, the finally block is executed, and then the engine continues to go through the functions in the call stack in order until the exception is handled properly or the application is terminated.
Also important to note is that the finally block will be executed even if the try or catch blocks execute a return statement.
Let’s look at the following example:
function foo1() {
try {
return true;
} finally {
return false;
}
}
By invoking the foo1() function, we get false as result, even though the try block has a return statement.
The same applies if we have a return statement in a catch block:
function foo2() {
try {
throw new Error();
} catch {
return true;
} finally {
return false;
}
}
Invoking foo2() also returns false.
Handling Exceptions in Asynchronous Code
We won’t go into detail about the internals of async programming in JavaScript here, but we will see how handling exceptions is done with “callback functions”, “promises”, and “async/await”.
async/await
Let’s define a standard function that just throws an error:
async function foo() {
throw new Error();
}
When an error is thrown in an async function, a rejected promise will be returned with the thrown error, equivalent to:
return Promise.Reject(new Error())
Let’s see what happens when foo() is invoked:
try {
foo();
} catch(err) {
// This block won’t be reached.
} finally {
// This block will be reached before the Promise is rejected.
}
Since foo() is async, it dispatches a Promise. The code does not wait for the async function, so there is no actual error to be caught at the moment. The finally block is executed and then the Promise rejects.
We don’t have any code that handles this rejected Promise.
This can be handled by just adding the await keyword when invoking foo() and wrapping the code in an async function:
async function run() {
try {
await foo();
} catch(err) {
// This block will be reached now.
} finally {
// This block will be reached at the end.
}
}
run();
Promises
Let’s define a function that throws an error outside of the Promise:
function foo(x) {
if (typeof x !== 'number') {
throw new TypeError('x is not a number');
}
return new Promise((resolve, reject) => {
resolve(x);
});
}
Now let’s invoke foo with a string instead of a number:
foo(‘test’)
.then(x => console.log(x))
.catch(err => console.log(err));
This will result in an Uncaught TypeError: x is not a number since the catch of the promise is not being able to handle an error that was thrown outside of the Promise.
To catch such errors, you need to use the standard try and catch clauses:
try {
foo(‘test’)
.then(x => console.log(x))
.catch(err => console.log(err));
} catch(err) {
// Now the error is handed
}
If foo is modified to throw an error inside of the Promise:
function foo(x) {
return new Promise((resolve, reject) => {
if (typeof x !== 'number') {
throw new TypeError('x is not a number');
}
resolve(x);
});
}
Now the catch statement of the promise will handle the error:
try {
foo(‘test’)
.then(x => console.log(x))
.catch(err => console.log(err)); // The error is handled here.
} catch(err) {
// This block is not reached since the thrown error is inside of a Promise.
}
Note that throwing an error inside a Promise is the same thing as using the reject callback. So it’s better to define foo like this:
function foo(x) {
return new Promise((resolve, reject) => {
if (typeof x !== 'number') {
reject('x is not a number');
}
resolve(x);
});
}
If there is no catch method to handle the error inside the Promise, the next function from the callback queue will be added to the stack.
Callback Functions
There are two main rules for working with the error-first callback approach:
- The first argument of the callback is for the error object. If an error occurred, it will be returned by the first
errargument. If no error occurred,errwill be set tonull. - The second argument of the callback is the response data.
function asyncFoo(x, callback) {
// Some async code...
}
asyncFoo(‘testParam’, (err, result) => {
If (err) {
// Handle error.
}
// Do some other work.
});
If there is an err object, it’s better not to touch or rely on the result parameter.
Dealing with unhandled exceptions
If your application uses third-party libraries, you have no control over how they deal with exceptions. There are cases when you might want to be able to deal with unhandled exceptions.
Browser
Browsers expose a window.onerror event handler that can be used for this purpose.
Here is how you can use it:
window.onerror = (msg, url, line, column, err) => {
// ... handle error …
return false;
};
This is what the arguments mean:
- msg — The message associated with the error, e.g.
Uncaught ReferenceError: foo is not defined. - url — The URL of the script or document associated with the error.
- lineNo — The line number (if available).
- columnNo — The column number (if available).
- err — The Error object associated with this error (if available).
When the function returns true, this prevents the firing of the default event handler.
There can be only one event handler assigned to window.onerror because it is a function assignment, and there can only be one function assigned to an event at a time.
This means that if you assign your own window.onerror, you will override any previous handler that might have been assigned by third-party libraries. This can be a huge problem, especially for tools such as error trackers, as they will most likely completely stop working.
You can easily work around this problem by using the following trick:
var oldOnErrorHandler = window.onerror;
window.onerror = (msg, url, line, column, err) => {
If (oldOnErrorHandler) {
// Call any previously assigned handler.
oldOnErrorHandler.apply(this, arguments);
}
// The rest of your code
}
Тhe code above checks if there was a previously defined window.onerror, and simply calls it before proceeding. Using this pattern, you can keep adding additional handlers to window.onerror.
This approach is highly compatible across browsers (it is supported even in IE6).
An alternative, which doesn’t require replacing handlers, is adding an event listener to the window object:
window.addEventListener('error', e => {
// Get the error properties from the error event object
const { message, filename, lineno, colno, error } = e;
});
This approach is much better, and also widely supported (from IE9 onwards).
Node.js
The process object from the EventEmmiter module provides two events for handling errors.
uncaughtException— emitted when an uncaught exception bubbles all the way back to the event loop. By default, Node.js handles such exceptions by printing the stack trace to stderr and exiting withcode 1. Adding a handler for this event overrides the default behavior. The correct use of the event is to perform synchronous cleanup of allocated resources (e.g. file descriptors, handles, etc) before shutting down the process. It is not safe to resume normal operation afterwards.unhandledRejection— emitted whenever aPromiseis rejected and no error handler is attached to the promise within a turn of the event loop. TheunhandledRejectionevent is useful for detecting and keeping track of promises that were rejected and which rejections have not yet been handled.
process
.on('unhandledRejection', (reason, promise) => {
// Handle failed Promise
})
.on('uncaughtException', err => {
// Handle failed Error
process.exit(1);
});
It’s really important that error handling is properly taken care of within your code. It’s equally important to understand unhandled errors so that you can prioritize and work on them accordingly.
You can do this on your own, which can be quite tricky due to the wide variety of browsers, and all of the different cases that need to be taken care of. Alternatively, you can use some third-party tool to do this for you. No matter what option you choose, it’s very important that you have as much information as possible about the error and the user context on how the error was triggered so that you can easily replicate it.
SessionStack is a solution that lets you replay JavaScript errors as if they happened in your browser. You can visually replay the exact user steps that led to the error, see the device, resolution, network, and all of the data that might be needed to connect the dots.
There is a free trial if you’d like to give SessionStack a try.
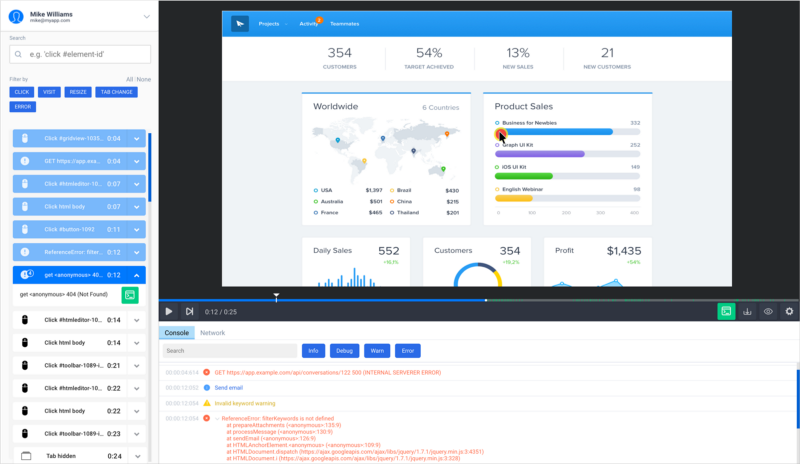
SessionStack replaying an error.
Resources:
- [https://www.sitepoint.com/exceptional-exception-handling-in-javascript/#:~:text=When%20a%20JavaScript%20statement%20generates,whatever%20function%20threw%20the%20exception](https://www.sitepoint.com/exceptional-exception-handling-in-javascript/#:~:text=When a JavaScript statement generates,whatever function threw the exception).
- https://www.tutorialspoint.com/es6/es6_error_handling.htm
- https://www.javascripttutorial.net/es6/promise-error-handling/